
Bank Telemarketing Analysis - Classification
Introduction
Ini adalah Final Project Purwadhika untuk Program Data Science dan Machine Learning. Dimana data didapatkan dari UCI yang dapat diaskes secara publik di sini. Project ini menggunakan Logistic Regression, Random Forest Classifier, dan XGBoost Classifier, dilakukan juga resampling menggunakan SMOTE dan Near-miss Algorithm.
Overview
Project ini terbagi menjadi lima bagian:
- Data cleaning and exploratory analysis
- Modelling
- Adjusting Threshold
- Feature Importances
- Model Deployment
Summary
Pada bagian pertama: saya membersihkan data, dimana di data ini terdapat missing value yang ditandai dengan data berisikan unknown dan non-existent, kemudian saya juga melakukan eksplorasi data yang berisikan rekomendasi-rekomendasi seperti memberitahu profiling orang-orang yang tepat dikontak dan ditawarkan deposito dan juga dilakukannya analisa statistik (normality test & significance test). Untuk lebih lengkapnya dapat dilihat di notebook ini
Kemudian pada bagian kedua: dilakukannya resampling menggunakan SMOTE dan near-miss. Yang saya juga melakukan eksplorasi model dari model default hingga model yang telah di tuning. Untuk lebih lengkapnya dapat dilihat di notebook ini untuk default dan untuk Model yang telah di-tuning dengan bantuan Randomized Search CV adalah notebook ini. Di project ini, model terbaik dilihat dari F1-macro terbaik, dikarenakan dataset ini termasuk kategori highly-imbalanced.
Selanjutnya pada bagian ketiga: saya melakukan adjusting threshold dengan bantuan precision-recall curve yang dapat dilihat lebih lengkapnya di notebook ini
Dan untuk bagian keempat: saya menunjukkan feature importances, yang dimakusdkan untuk memberitahu fitur apa yang paling membantu model melakukan klasifikasi. Yang juga dapat membantu bank untuk menyusun strategi selanjutnya. Untuk lengkapnya ada di notebook ini
Sedangkan di bagian kelima: Karena tujuan akhir project ini juga membuat dashboard. Maka saya mencoba untuk melihat gambarannya, yang lengkapnya dapat dilihat di notebook ini
Result
Bussiness Insight
Dari eksplorasi dapat disimpulkan bahwa:
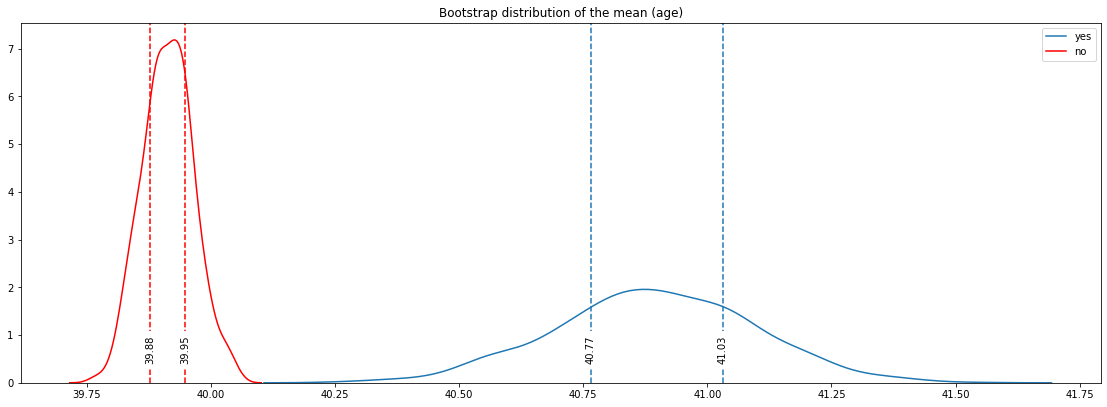
- Bank seharusnya target ke anak-anak muda yang masih berkuliah atau orang-orang tua yang sudah pensiun. Analisanya adalah anak-anak muda masih belum memilki banyak pengetahuan yang berurusan dengan investasi. Maka deposito akan menjadi alat investasi yang cocok untuk mereka, mengingat deposito memiliki resiko yang rendah. Begitu juga dengan orang-orang tua yang sudah pensiunan, deposito juga menjadi alat investasi yang cocok buat mereka, karena deposito punya resiko yang rendah. Dan dari Bootstrap Distribution untuk fitur umur juga memperlihatkan hal yang mirip, orang-orang yang melakukan deposito relatif lebih muda daripada yang menolak untuk melakukan deposito. Visualisasinya dapat dilihat di bawah:
- Bulan maret menjadi bulan terbaik untuk mengontak nasabah-nasabah. Karena dalam notebook ini, ditunjukkan bahwa tingkat kesuksesan tertinggi ada pada bulan maret. Visualisasinya dapat dilihat di bawah:
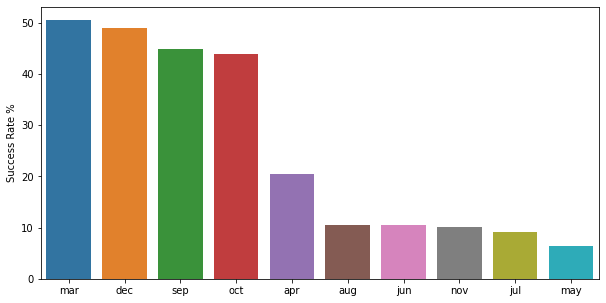
- Dari segi socio-economics, di dataset ini peluang orang-orang melakukan deposito lebih tinggi saat Euribor rendah, CCI rendah, CPI rendah, Jumlah pegawai bank rendah, dan tingkat variasi pada pegawai bank rendah. Sebetulnya ini dapat dijadikan diskusi, mengingat ternyata peluang orang-orang melakukan deposito lebih tinggi saat Euribor rendah. Kenapa? Karena Euribor adalah alat yang biasa dipakai bank untuk menentukan suatu suku bunga, suku bunga deposito maupun suku bunga pinjaman. Jadi terlihat adanya kejanggalan, melihat saat Euribor rendah yang artinya suku bunga deposito rendah, tapi malah peluang orang-orang melakukan deposito lebih tinggi saat Euribor merendah. Yang distribusinya dapat dilihat di bawah:
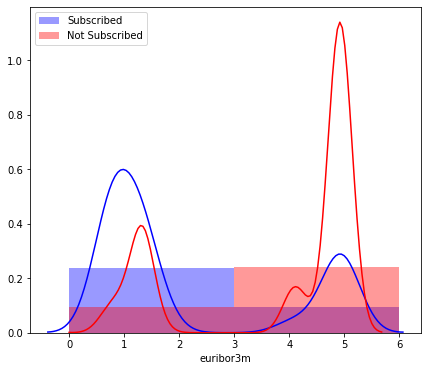
Untuk lebih lengkapnya ada di notebook ini.
Evaluation Metrics
Dikarenakan data termasuk kategori highly-imbalanced, dan menurut saya ini juga permasalahan bisnis yang highly-imbalanced. Maka evaluasi metrik objektif pada project ini adalah f1_macro. Atau sebagai alternatif, orang lain mungkin juga ada yang ingin melihat Matthews Correlation Coefficient sebagai evaluasi metrik utamanya karena saya menunjukkannya juga. Tapi f1_macro yang saya gunakan di project ini.
| Classifier | Macro F1 Score | Macro Recall | Macro Precision | Matthews correlation coefficient |
|---|---|---|---|---|
| Logistic Regression | 0.639009 | 0.604403 | 0.781723 | 0.343002 |
| Random Forest Classifier (experiment 1) | 0.618911 | 0.587297 | 0.816189 | 0.332280 |
| Random Forest Classifier (experiment 2) | 0.622705 | 0.590151 | 0.813908 | 0.336447 |
| XGBoost Classifier (experiment 1) | 0.648942 | 0.611661 | 0.796106 | 0.363668 |
| XGBoost Classifier (experiment 2) | 0.638802 | 0.603841 | 0.787810 | 0.345753 |
| Logistic Regression (with SMOTE) | 0.683400 | 0.738456 | 0.658925 | 0.389341 |
| Random Forest Classifier (experiment 1 with SMOTE) | 0.700277 | 0.745260 | 0.680617 | 0.420733 |
| Random Forest Classifier (experiment 2 with SMOTE) | 0.704133 | 0.745017 | 0.678390 | 0.416265 |
| XGBoost Classifier (experiment 1 with SMOTE) | 0.701783 | 0.742834 | 0.678390 | 0.416265 |
| XGBoost Classifier (experiment 2 with SMOTE) | 0.705274 | 0.746266 | 0.681643 | 0.423000 |
Catatan: Terdapat dua eksperimen pada model Random Forest dan XGBoost, itu dikarenakan hyperparameter yang diberikan RandomizedSearchCV masih membuat model mengalami overfitting. Itu kenapa saya melakukan eksperimen menggunakan bantuan Validation Curve dan pengetahuan saya tentang hyperparameter-hyperparameter pada model Random Forest dan Xtreme Gradient Boosting.
Model terbaik ada di antara Random Forest Classifier (experiment 2 with SMOTE) dan XGBoost Classifier (experiment 2 with SMOTE). Kemudian project ini masuk ke adjusting threshold yang dimana, saya lebih melihatnya dari segi bisnis. Dimana saya ingin model yang punya recall tinggi atau False Negative (FN) yang rendah. Dan pada akhirnya, threshold yang digunakan adalah 0.33 dengan Random Forest Classifier (experiment 2 with SMOTE) adalah model terbaik. Ini precision-recall curve untuk model Random Forest Classifier (experiment 2 with SMOTE):
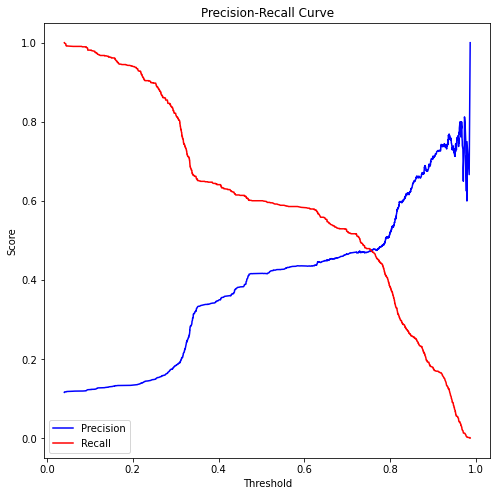
Sedangkan untuk model XGBoost Classifier (experiment 2 with SMOTE) precision-recall curvenya dapat dilihat di notebook ini
Final Model
Final Model yang saya gunakan diakhir adalah Random Forest Classifier dengan SMOTE, dengan learning curve:
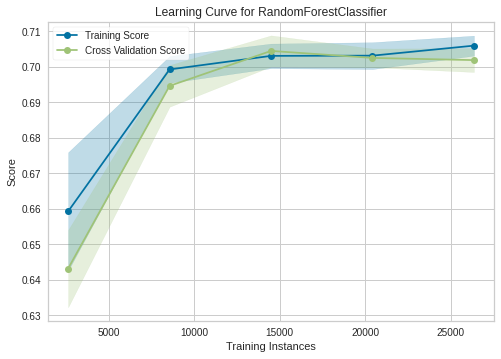
Memang learning curve, terlihat terlalu besar ‘penalty’nya. Namun model tidak mengalami overfitting. Sedangkan untuk validation curvenya, saya hanya menunjukkan dua parameter yaitu max_depth dan min_samples_leaf
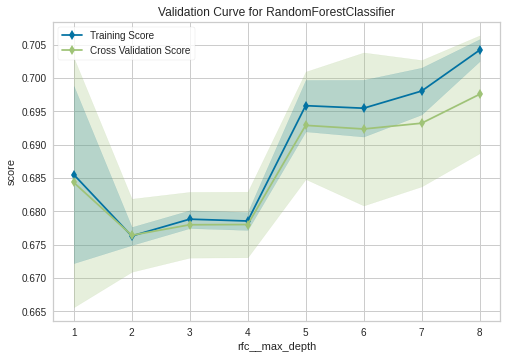
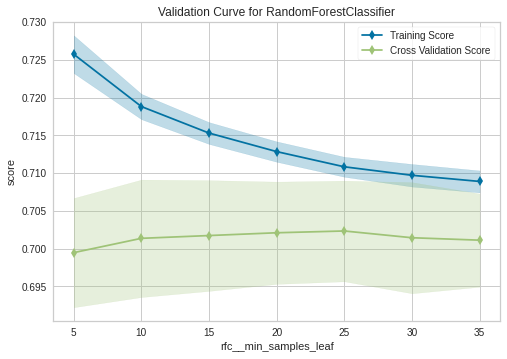
Untuk lebih lengkapnya, dapat dilihat di notebook ini
Reference
[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, June 2014</p>