Credit Risk Analysis - Classification and Clustering
Source Dataset: https://archive.ics.uci.edu/ml/datasets/Statlog+%28German+Credit+Data%29
Overview
Project ini terbagi menjadi tiga bagian, EDA, Clustering dan Classification. Pada bagian EDA, saya mencoba untuk membersihkan data dan melakukan eksplorasi data. Kemudian pada bagian clustering, di project ini menggunakan K-Means Clustering, Agglomerative Hierarchical Clustering, dan DBSCAN yang bertujuan untuk menunjukkan kluster-kluster dan karakteristik orang-orang pada dataset ini. Sedangkan pada bagian classification, project ini menggunakan Random Forest Classifier dan XGBoost Classifier.
Summary
Bussiness Insight
Dari algoritma clustering yang telah saya gunakan dari K-means, Agglomerative Clustering, DBSCAN. Saya merasa untuk bussiness insight, Agglomerative Clustering dan DBSCAN lebih berguna daripada K-Means. Dikarenakan dari Agglomerative Clustering dan DBSCAN benar-benar dapat memberikan gambaran setiap segmen dengan baik. Misalnya, pada Agglomerative Clustering kita dapat empat kluster yang bisa dibilang menggambarkan semua segmen (dari muda sampai tua). Sedangkan DBSCAN dapat memperlihatkan multivariate outliers pada dataset ini. Yang bisa ditentukan pemberi pinjaman apakah dia beresiko atau tidak. Untuk ringkasannya ada di bawah. Namun untuk lebih lengkapnya ada di notebook ini.
Clustering
K-Means
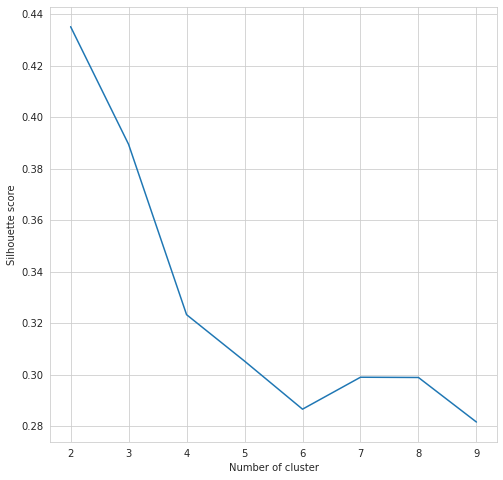
Dari grafik di atas menunjukkan adanya dua kluster di dataset ini.
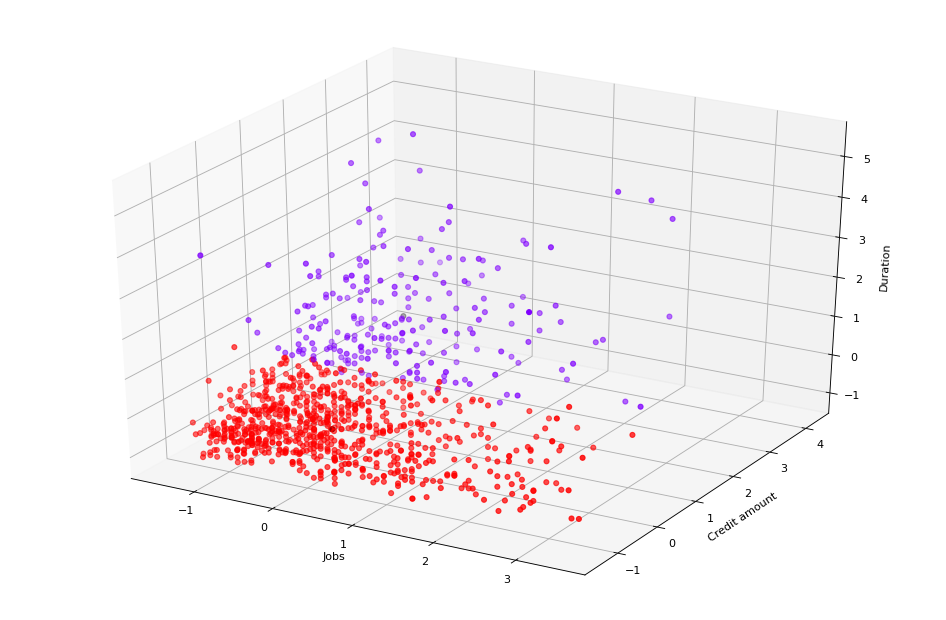
Dimana :
- Cluster 0 adalah orang-orang yang punya jumlah kredit yang besar dan berdurasi panjang.
- Cluster 1 adalah orang-orang yang punya jumlah kredit yang sedikit dan berdurasi pendek.
Sebetulnya dari kluster ini bisa dilihat juga rata-rata menyicilnya, orang-orang pada kluster 0 menyicil kredit lebih banyak daripada kluster 1.
Agglomerative Clustering
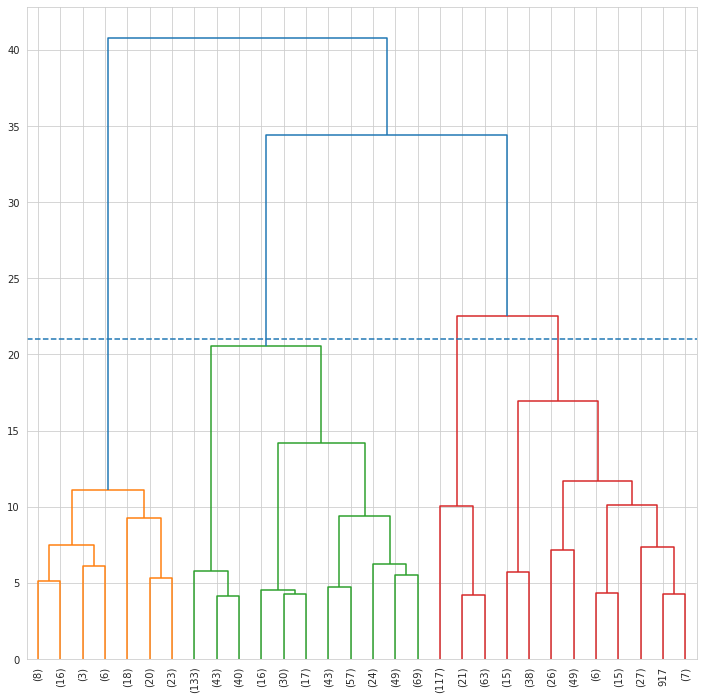
Dari Dendogram di atas menunjukkan adanya empat kluster.
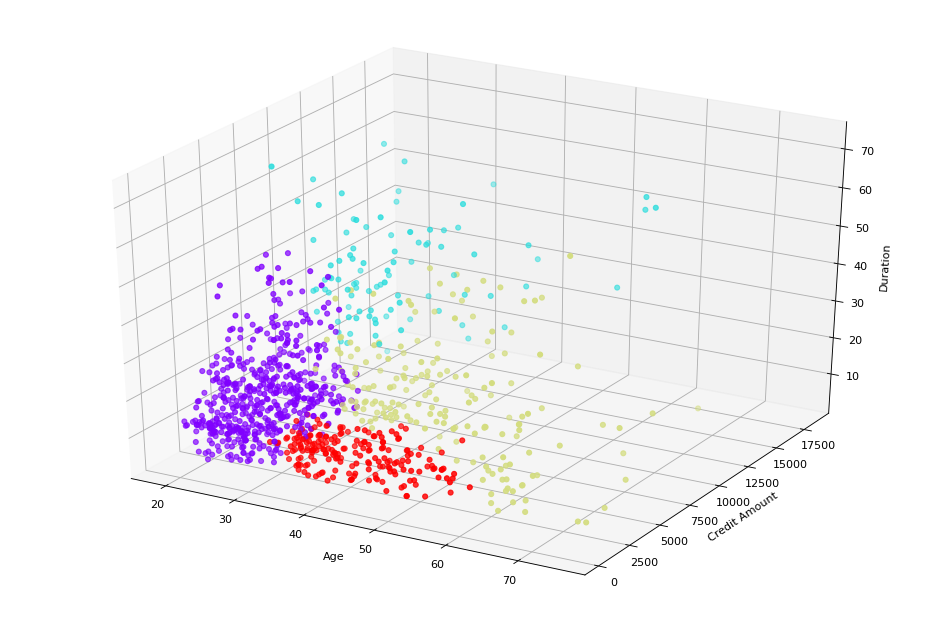
- Cluster 0 adalah orang-orang berumur muda atau bisa dikategorikan (young-adults) dengan jumlah kredit yang sedikit dan berdurasi relatif pendek.
- Cluster 1 adalah orang-orang yang berumur relatif ‘tua’ dengan jumlah kredit yang lumayan besar dan berdurasi panjang.
- Cluster 2 adalah orang-orang yang bisa dibilang ‘tua’ dengan jumlah kredit yang relatif sedang dan berdurasi relatif pendek.
- Cluster 3 adalah orang-orang yang juga bisa dibilang ‘tua’, dengan jumlah kredit yang kecil dan berdurasi pendek.
DBSCAN Clustering
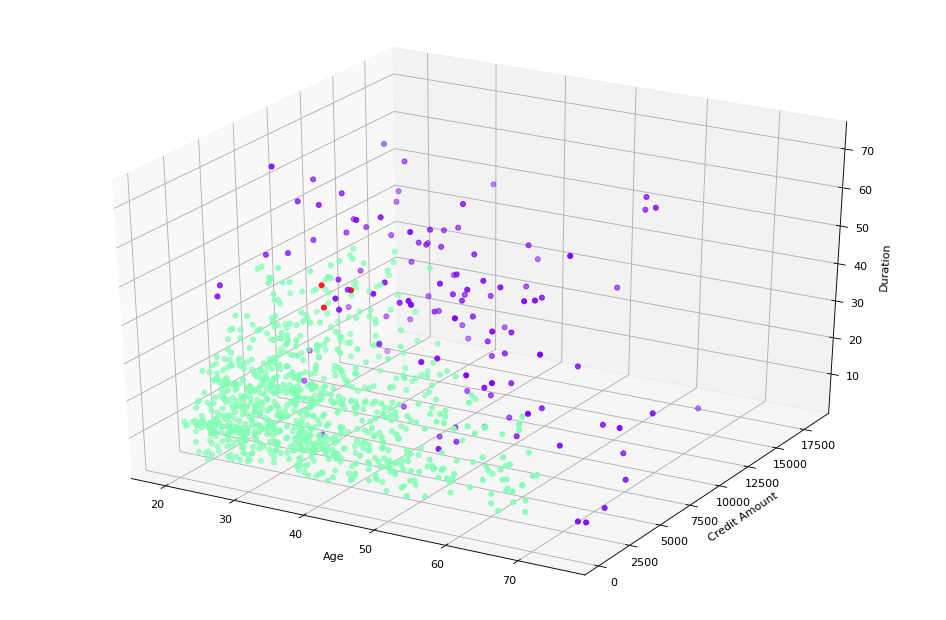
Dari DBSCAN terdapat tiga cluster, dimana:
- Cluster 1 : adalah orang-orang yang berumur cukup tua dengan jumlah kredit relatif sedang tapi berdurasi panjang. Satu hal yang saya senangi dari DBSCAN, mereka juga terkadang dipakai untuk menemukan multivariate outliers. Dan ini bisa dijadikan contoh (bisa jadi contoh baik atau buruk tergantung menurut pemberi pinjaman), karena orang-orang yang berada di kluster ini bisa dibilang agak jarang terjadi. Mengingat jumlah kredit yang sedang tapi berdurasi panjang. Ini bisa dibilang panjang mengingat jumlah kreditnya relatif tidak terlalu banyak.
- Cluster -1 : adalah orang-orang yang berumur tua dengan jumlah kredit yang relatif besar dan berdurasi relatif panjang. Jumlah di cluster ini tidak terlalu banyak.
- Cluster 0 : adalah orang-orang yang berumur relatif tua paling mendominasi di dataset ini, orang-orang yang punya kredit sedikit dan berdurasi pendek.
Evaluation Metrics for Classification model
Metrik Evaluasi pada project ini yang digunakan adalah : F1 Score, recall, precision, ROC-AUC Score, dan Matthews correlation coefficient. Dikarenakan dataset ini tidak termasuk kategori dataset yang highly-imbalanced, maka model terbaik dapat dipilih dari ROC-AUC Score tertinggi. Dan ini hasilnya:
| Classifier | F1 Score | recall | precision | ROC-AUC Score | Matthews correlation coefficient |
|---|---|---|---|---|---|
| XGBoost Classifier | 0.820359 | 0.978571 | 0.706186 | 0.514286 | 0.076753 |
| Random Forest Classifier | 0.827381 | 0.992857 | 0.709184 | 0.521429 | 0.140283 |
Dari hasil di atas, dapat dilihat bahwa Random Forest memiliki ROC-AUC Score lebih tinggi daripada XGBoost. Dimana dapat disimpulkan bahwa Random Forest, classifier yang lebih baik dalam pembandingan antara kedua model. Namun sayangnya keduanya punya nilai Matthews correlation coefficient yang mendekati 0. Tapi kabar baiknya, mereka memiliki recall yang sama-sama tinggi, yang artinya keduanya dapat menebak dengan baik orang-orang yang beresiko untuk diberi pinjaman.
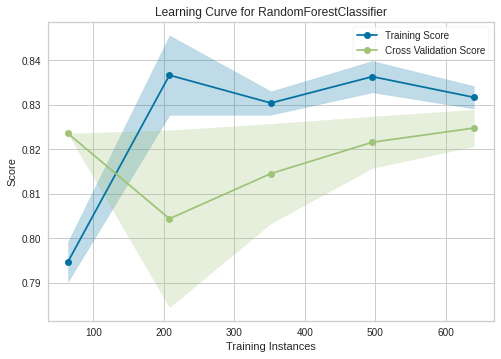
Learning Curve
Learning Curve yang akan ditunjukkan hanya Random Forest Classifier, sedangkan untuk XGBoost Classifier terdapat di notebook ini